基准与现实的差距
在AI发展热潮的背景下 自去年8月开始 Claude 3.7这类AI大模型 在官方基准测试中 宣称取得了巨大进步 然而 在实际应用当中 提升却非常有限 许多创业公司 在开发应用时 满心期待新模型能带来革新 但使用后却发现 与宣传相差甚远 这样的落差 实在让人失望
众多科技创业团队有反馈。每次新大模型发布。看基准数据时很亮眼。但真用到项目里。效果就会大打折扣。比如一些做智能客服应用的企业。更换新模型后。客户问题解决率没有实质性提升。响应速度也没有实质性提升。
原因分析之作弊嫌疑
大模型在基准测试和实际应用中有差异。这让人怀疑基准测试存在作弊情况。部分模型开发者为让数据好看。可能会用不正当手段。这种行为如同学生考试作弊。虽能得高分。但并无真正实力。
有行业专家指出,一些模型或许提前对测试题进行了“训练”。这就如同提前知晓了考试答案一样。这种不诚信的行为,既误导了投资者,又误导了开发者。同时,它还阻碍了AI行业健康发展,致使真正有价值的研究难以凸显出来。
基准实用性之困
现有的基准测试或许没法衡量模型在实际场景里的实用性。基准测试就好比是一场“纸上谈兵”。它只关注某些特定指标。它不能反映模型在复杂实际环境中的表现。
比如在网络安全评估等实际应用当中,测试主要关注孤立代码块问题。它与真正的网络攻击场景差别很大。像CTF评估会为模型给出明确的挑战描述。然而实际网络威胁是千变万化的。这就导致测试结果与实际防护能力严重不相符。

对齐瓶颈问题
模型本身或许挺聪明。然而在对齐方面存在瓶颈。大模型跟人类需求以及实际场景对齐时效果不好。好比有能力但方向有误。它在某些抽象任务上可能表现出色。但解决具体问题时就显得力不从心。
软件工程师工作时,不少大模型难以很好理解复杂业务逻辑与需求。其生成的代码,语法可能正确。然而在实际应用里,却无法满足项目要求。也不能与实际生产系统有效对齐,进而造成了浪费。
实际应用提升有限
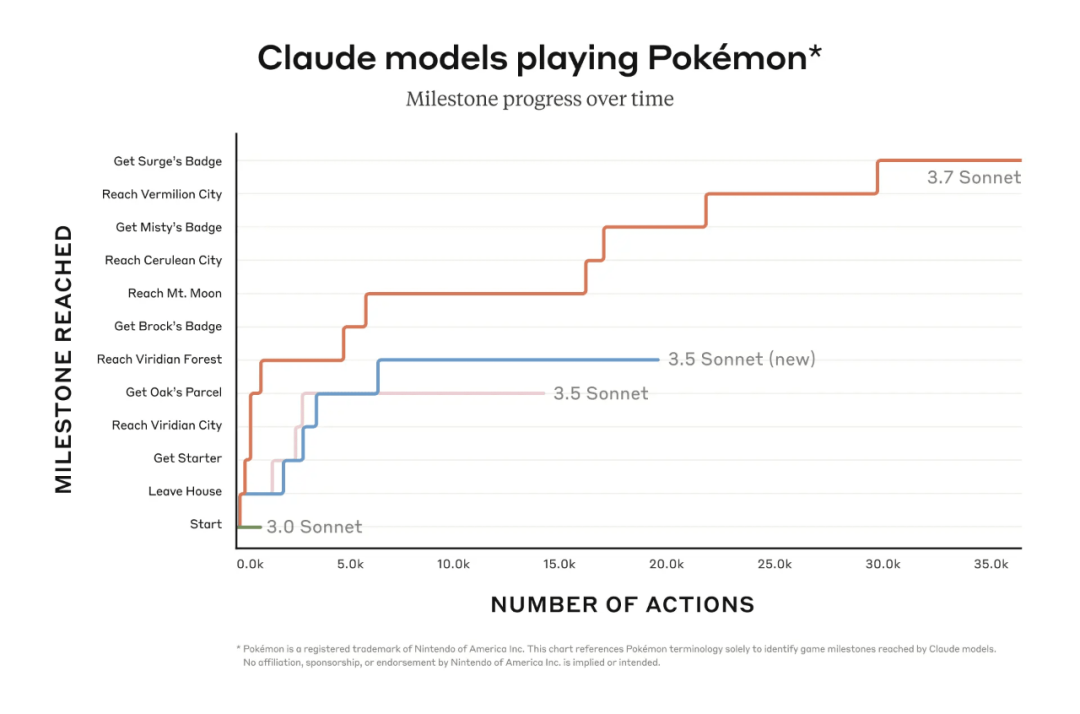
除了少量版本有小幅度提高外,新模型对内部基准影响不大。新模型对开发人员发现新错误的能力影响也不大。各大公司不断推出新模型。然而开发者的实际体验没有明显提升。
不少开发者称,新模型对解决日常工作里的代码问题没啥作用。在实际项目中,仍得花大量时间手动检查问题。新模型也没带来预期的智能辅助效果,提升开发效率也有限。
衡量标准的缺失
业界目前不清楚怎样衡量模型的智力。也不清楚如何衡量模型的实际应用价值。要是模型大多局限于聊天机器人。那么在管理公司时。衡量标准缺失会是个巨大问题。在制定公共政策时。衡量标准缺失同样会是个巨大问题。
当AI用于企业管理决策,很难判断模型给出的建议是不是合理可行。要是没有科学的衡量标准,也许会造成错误决策,给企业带来损害。当把AI应用在公共政策制定方面,后果会更严重。
你觉得该怎么去建立一套科学又合理的AI大模型衡量标准?欢迎在评论区分享你的看法。也别忘记给本文点赞。还要分享本文!



